When Webhooks Go Out of Order and How to Fix It
Webhooks is a deceivingly complex topic. They look simple… until they quietly corrupt your data. One of the sneakiest problems are events that arrive out of order.
I won’t get into all the different elements that need to be considered when building webhooks. However, I do want to talk about one specifically that can be really painful if you’re not aware of this small, but crucial characteristic about webhooks:
Webhooks don’t always arrive in the order that you would expect… And that’s expected.
At some point in your journey, your payment.created event will arrive after your payment.updated event, and you will have to deal with it on your side.
Distributed systems don’t promise perfect order. Stripe, for example, explicitly states that event order isn’t guaranteed, and there’s many examples online of people talking about this on reddit, on forums or on GitHub where people have ran into this issue.
A Naive Handler
def handle_payment_updated(event)
payment = Payment.find_by(stripe_id: event.data.object.id)
payment.update!(status: event.data.object.status)
end
This seems okay during dev. But if updated arrives before created, payment is nil, and your system quickly drifts away from the provider’s source of truth.
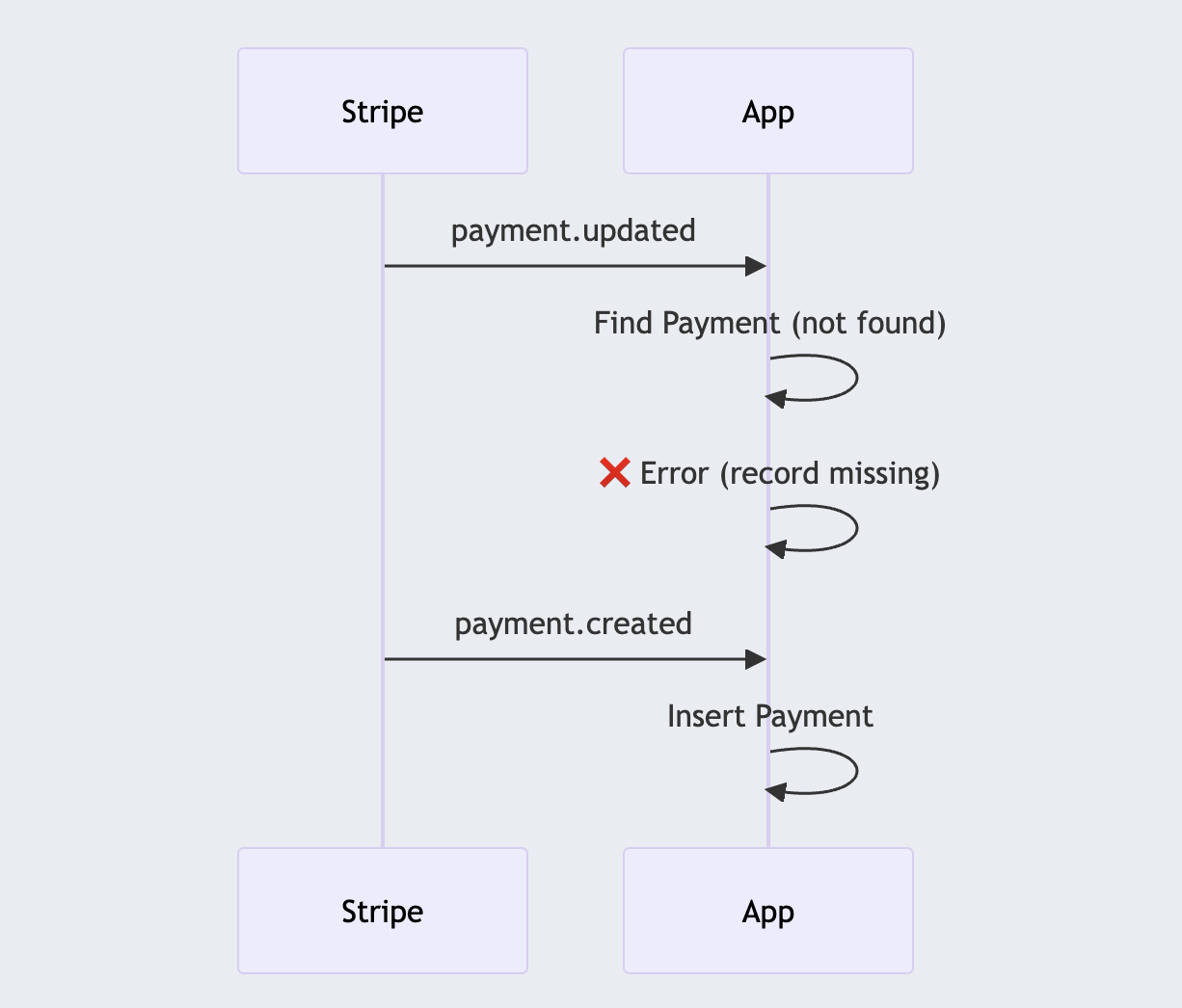
In the example above, the payment.updated event arrives before the payment.created event, and the payment.updated event is dropped.
Fetching again
A way to get around this, (and the most resilient in my opinion) is to fetch the resource again so you can grab the latest state. I find it helpful to change mindset to acknowledge that webhooks are notifications, not the source of truth.
def handle_payment_updated(event)
id = event.data.object.id
payment = Payment.find_by(stripe_id: id)
Payment.sync id
end
# payment.rb
def self.sync(payment_id)
object = ::Stripe::Payment.retrieve(payment_id)
payment = Payment.find_or_initialize_by(remote_id: payment_id)
payment.amount = object.amount
payment.status = object.status
payment.save!
end
Now, even if events shuffle, you always reconcile against the provider’s canonical state.
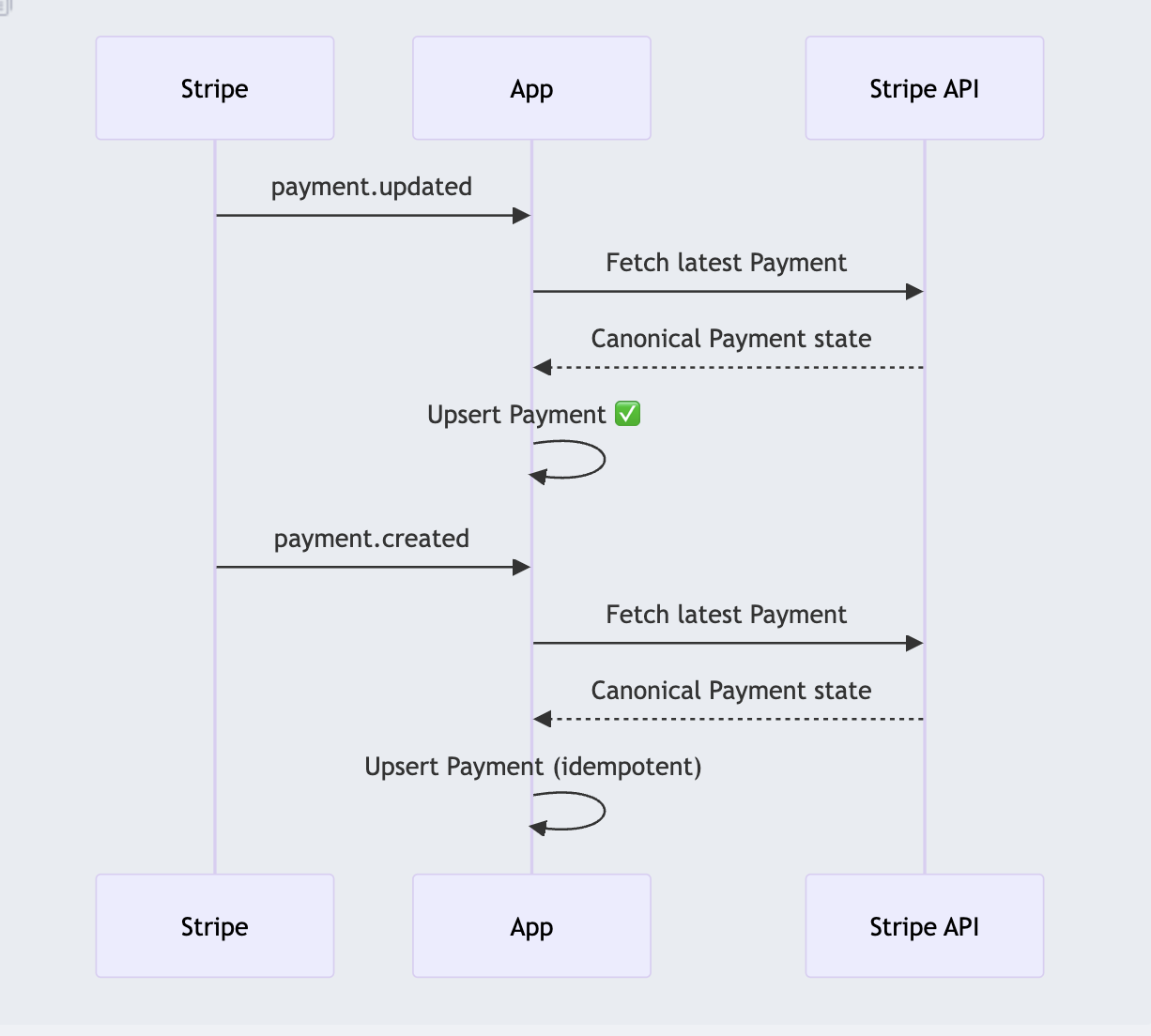
Here, the payment.updated event arrives after the payment.created event, and the payment.updated event is applied. This way our app provides a consistent view of the world.
Other Approaches & Trade-offs
There isn’t a single “correct” way to handle out-of-order webhooks. Fetching from the provider is the most resilient, but it’s worth knowing what else is out there.
Event versioning / timestamps
Some developers rely on the event’s created_at timestamp to ignore stale updates.
✅ Simple to implement.
❌ Risky if events are truly missing — you might silently drop an important state change.
Event buffering / queuing
You can queue incoming events, sort them by creation time, then apply them in order.
✅ Preserves sequence when traffic is heavy.
❌ Adds complexity. Queues can back up, and you still can’t guarantee you got all events.
Idempotent upserts
Instead of updating blindly, always “upsert” using an external ID (find_or_create + update_or_insert).
✅ Prevents crashes when update arrives before create.
❌ Doesn’t fix the stale data problem.
Ignore certain states
For example, only update when an event reflects a terminal state (succeeded, failed).
✅ Cuts down noise and risk from transient states.
❌ Loses visibility into intermediate states.
👉 My personal preference is to use reconciliation as the default, and layer in one of these if you have specific performance or product needs.
Isn’t fetching expensive?
Yes, that’s fair concern. And sure, if you naively hit the API on every single webhook, it can add up. The trick is to be smart about it. Batch requests if your provider supports it, debounce events for the same resource so you only fetch once per burst, and lean on caching or ETags so you don’t download data that hasn’t changed. Add a periodic sweep job to backfill anything you might have missed, and suddenly those “extra” API calls aren’t nearly as scary. In practice, you usually end up making fewer writes overall, because one reconciliation replaces a whole string of noisy updates.
Conclusion
The reason I prefer fetching again over the other tricks is because it always gets you back to the truth. Timestamps, queues, or idempotent upserts can all help in certain cases, but they rely on the assumption that you’ll see every event in the right order. In the real world, events go missing, arrive late, or show up twice. By treating webhooks as just a nudge and then pulling the actual state from the provider, you make your system self-healing. Even if things get messy in transit, you’ll always reconcile against the source of truth and end up consistent. That peace of mind is worth a few extra API calls.